
Go: Stress testing our service
As we implemented our service that adds pageviews to the database, we realize an unfortunate circumstance. Each insert query takes about 12ms, which means our request rate, at least per single CPU core, is poor. We’re talking about 83 req/s poor.
But as we know that scaling isn’t linear and you shouldn’t judge a single request, we need to perform some stress testing to give us a better idea of where we are.
Now, the best practices of stress testing suggest that you need isolation. In our case this means that we would need to have at least 3 servers running, one with our stress testing tool, another with our service, and another with the database, and possibly a fourth server with APM. This way the benchmarks won’t be tainted.
Now, considering I’m doing this on a low-end-ish thin client machine, we can be sure that my stress tests here will be tainted. I’m running everything on a single machine, along with a full featured desktop, so the measurements will be skewed, but hopefully they will be good enough for some basic evaluation.
Setting up our stress test
What we need to do first is figure out how to stress test some requests to our service. We need a tool that supports POST requests with custom payloads, concurrency, and something that will spit out a total request rate at the end.
A short search leads us to wrk, and there seems to be a modern up to date docker image
with wrk available (skandyla/wrk), so let’s
try to use it straight from docker. In order to craft a POST request, a lua script for
it needs to be created. Let’s create test.lua:
wrk.method = "POST"
wrk.headers['Content-Type'] = "application/json"
wrk.body = '{"property":"news","section":1,"id":1}'
And let’s create a test.sh, that also takes care of getting our service container IP:
#!/bin/bash
function get_stats_ip {
docker inspect \
microservice_stats_1 | \
jq -r '.[0].NetworkSettings.Networks["microservice_default"]'.IPAddress
}
url="http://$(get_stats_ip):3000/twirp/stats.StatsService/Push"
docker run --rm --net=host -it -v $PWD:/data skandyla/wrk -d15s -t4 -c400 -s test.lua $url
The command will run tests for 15 seconds, 4 threads, 400 connections, and run the script
test.lua for each request. Running ./test.sh against our service gives us this:
Running 15s test @ http://172.22.0.5:3000/twirp/stats.StatsService/Push
4 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 224.79ms 256.55ms 1.56s 88.49%
Req/Sec 579.91 191.59 1.26k 69.63%
34493 requests in 15.04s, 5.54MB read
Socket errors: connect 0, read 0, write 0, timeout 90
Non-2xx or 3xx responses: 17834
Requests/sec: 2293.06
Transfer/sec: 377.23KB
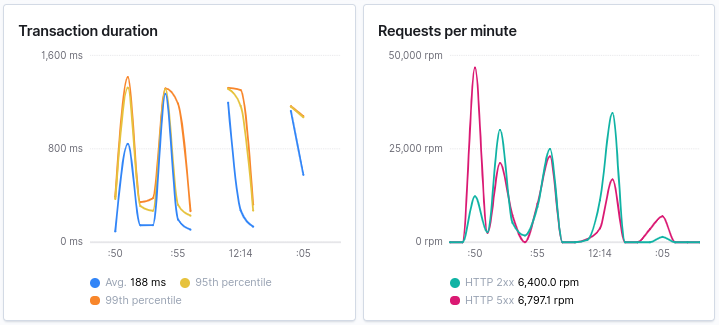
It seems that stress testing our service resulted in 17834 errors out of 34493 requests, along with 90 timeout errors. That is an error rate of about 52%. Since we are using APM, we can check what kind of errors are logged and start fixing the service.
The APM graphs confirm the error rate:
The errors tab also gives us some insight into the errors:
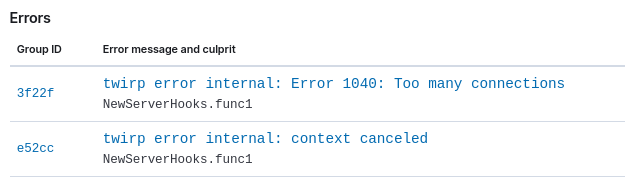
Resolving detected errors
The Error 1040: Too many connections is tunable both on the MySQL side, and the Go side.
On the Go side, we have the following options to tune MySQL usage on our DB instance:
- SetMaxOpenConns() - Set a maximum number of connections the service will hold open,
- SetMaxIdleConns() - Sets the most idle connections we can have open at any time,
- SetConnMaxLifetime() - Sets the time how much the connection can stay open for
All of these options tune our database usage. By default, there is no limit to the number
of connections that can be opened. If we set a limit with SetMaxOpenConns, a connection
must be freed up, so it can be reused. Generally you want this limit to be high, because
you don’t want to wait on connections too much if the pool is too small.
We want to simulate real life behaviour of the application to estimate the number of connections that work for our case. A stress test isn’t real life behaviour, so let’s just blindly set it to something highly unreasonable. Since we already set 400 connections as our target for the stress test, let’s double that on the back-end for our SQL connections.
By default, SetMaxIdleConns only allows 2 idle connections, meaning that there would be a
lot of churn as soon as clients go idle. We don’t want to throw away idle connections as they
die down, or at least not so fast, so we will set this value to the same as SetMaxOpenConns.
This doesn’t mean that the connection won’t be closed (there’s also MySQL timeout for that).
And finally, SetConnMaxLifetime is not set by default, meaning any connection that is opened
and isn’t reaped with SetMaxIdleConns can be reused within the duration set here.
Connection clean up operations run every second, so we will also reduce stress on the cleanup, if we can hold the connections open for a longer time. This one is up to you, but generally unless there’s a good technical reason for setting a max collection lifetime, like a ProxySQL load balancer in front of your MySQL cluster, you probably don’t need to change this.
Open up db/connect.go and replace ConnectWithOptions:
// ConnectWithOptions connect to host based on ConnectionOptions{}
func ConnectWithOptions(ctx context.Context, options ConnectionOptions) (*sqlx.DB, error) {
credentials := options.Credentials
if credentials.DSN == "" {
return nil, errors.New("DSN not provided")
}
if credentials.Driver == "" {
credentials.Driver = "mysql"
}
credentials.DSN = cleanDSN(credentials.DSN)
connect := func() (*sqlx.DB, error) {
if options.Connector != nil {
handle, err := options.Connector(ctx, credentials)
if err == nil {
return sqlx.NewDb(handle, credentials.Driver), nil
}
return nil, errors.WithStack(err)
}
return sqlx.ConnectContext(ctx, credentials.Driver, credentials.DSN)
}
db, err := connect()
if err != nil {
return nil, err
}
db.SetMaxOpenConns(800)
db.SetMaxIdleConns(800)
return db, nil
}
And let’s configure our database to have a maximum connection limit of 1000 connections.
Edit docker-compose.yml and update the database definition to this:
db:
image: percona/percona-server:8.0.17
command: [
"--max_connections=1000"
]
environment:
MYSQL_ALLOW_EMPTY_PASSWORD: "true"
MYSQL_USER: "stats"
MYSQL_DATABASE: "stats"
MYSQL_PASSWORD: "stats"
restart: always
Rebuild the docker images for our service with make && make docker and
re-run docker-compose up -d, and finally, let’s run our benchmark again:
Running 15s test @ http://172.22.0.5:3000/twirp/stats.StatsService/Push
4 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 185.91ms 158.08ms 1.47s 94.41%
Req/Sec 590.52 261.76 1.33k 62.03%
34813 requests in 15.05s, 3.62MB read
Requests/sec: 2313.32
Transfer/sec: 246.24KB
It seems we resolved all of our connection/response errors here. There are some 5xx errors still reported in APM which we need to look at.
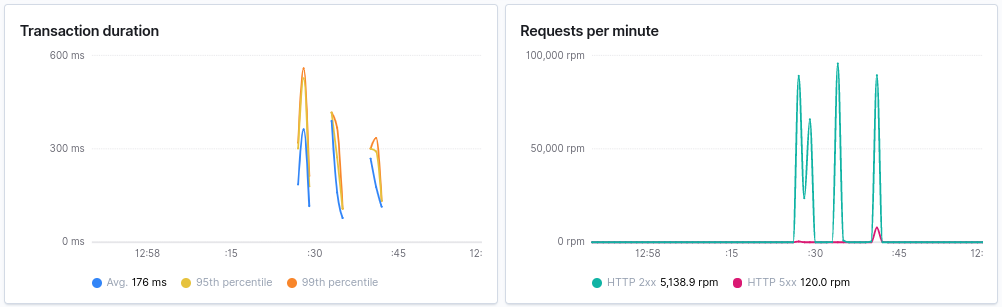
Note: the request rate is strangely jagged and not sustained as we would like. I’d guess this comes from queueing on the network level, but we won’t investigate it at this point.
Removing context cancellation
We are still getting twirp error internal: context canceled. Now, the issue with request
cancelation is that even the stack trace doesn’t help much when you want to figure out where
the context was canceled from, or even which context it’s supposed to be.
Given this stack trace:
gocontext.go in CaptureError at line 131
twirp.go in NewServerHooks.func1 at line 13
stats.twirp.go in callError at line 795
stats.twirp.go in writeError at line 376
stats.twirp.go in (*statsServiceServer).writeError at line 138
stats.twirp.go in (*statsServiceServer).servePushJSON at line 220
stats.twirp.go in (*statsServiceServer).servePush at line 186
stats.twirp.go in (*statsServiceServer).ServeHTTP at line 168
wrap.go in WrapWithIP.func1 at line 38
We might asume that the error originated from twirp, given the twirp error internal message,
but when we read the code we find this little bit:
// Non-twirp errors are wrapped as Internal (default)
twerr, ok := err.(twirp.Error)
if !ok {
twerr = twirp.InternalErrorWith(err)
}
So, our context canceled error came from our Push() function and is wrapped into a twirp internal error.
And we see that the only function it could have come from is _, err = svc.db.NamedExecContext(ctx, query, row).
One might think that this issue is database related, but it isn’t. There’s a simpler explanation: the request Context() function is cancellable and is cancelled as soon as the client drops the connection. The errors show up at the tail end of our stress test, so we can make an educated guess and say that the last few connections wrk makes, are closed forcefully and thus cancel the request.
Let’s verify our guess with some godoc sleuthing (http.Request.Context()):
For incoming server requests, the context is canceled when the client’s connection closes, the request is canceled (with HTTP/2), or when the ServeHTTP method returns.
In our case, we don’t want to use context cancellation here, our Push request already has all the data that needs to be logged to the database, so resolving the issue means that we need to provide a context without the cancellation and let Push() finish regardless.
We also need to keep the context values we have, so we can log the span correctly into APM.
We can’t just use a context.Background(), we need to provide our own context implementation
that keeps all the values which are already set by the APM HTTP handler wrapper.
Let’s provide our context without timeout/cancellation. We need to implement two functions from the interface, while the rest can stay as is. We can use embedding, so we don’t implement the complete context interface, but only the two functions required.
Navigate to the internal package and move context.go to context_ip.go, and create a
new context.go file with the following contents:
package internal
import (
"context"
)
type ctxWithoutCancel struct {
context.Context
}
// Done returns nil (not cancellable)
func (c ctxWithoutCancel) Done() <-chan struct{} { return nil }
// Err returns nil (not cancellable)
func (c ctxWithoutCancel) Err() error { return nil }
// ContextWithoutCancel returns a non-cancelable ctx
func ContextWithoutCancel(ctx context.Context) context.Context {
return ctxWithoutCancel{ctx}
}
We are only partially wrapping the provided context here, so we override Done and Err,
but don’t touch the provided Deadline or Value. Those remaining function calls will go
to the original context that we embedded here.
We can fix our Push function now to clear the context cancellation:
// Push a record to the incoming log table
func (svc *Server) Push(ctx context.Context, r *stats.PushRequest) (*stats.PushResponse, error) {
ctx = internal.ContextWithoutCancel(ctx)
...
From now on, each request that reaches Push() will be completed, regardless if the context for the request was cancelled. Depending on if you wish to still error out on some sort of timeout value, you can add a context.WithTimeout call after this one.
Now, let’s make two changes to our wrk script.
- Let’s use -t60s so we can test for a longer time period,
- Let’s use -c100 so we use a bit less connections overall
Rebuild and rerun the service, and run the test again:
Running 1m test @ http://172.22.0.5:3000/twirp/stats.StatsService/Push
4 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 47.69ms 11.86ms 143.28ms 73.10%
Req/Sec 527.04 85.10 800.00 73.25%
125930 requests in 1.00m, 13.09MB read
Requests/sec: 2097.16
Transfer/sec: 223.23KB
We can look at APM and see that zero errors have been logged during this stress test run. This means we have succesfully resolved this issue.
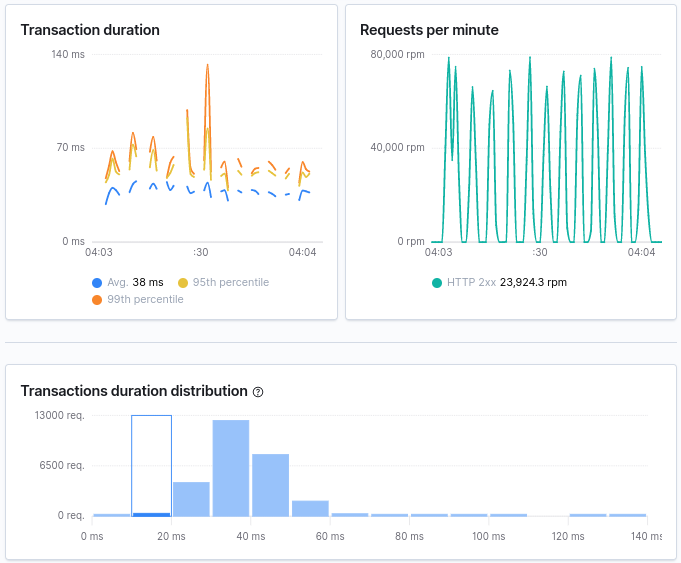
Wrapping up
You can already see the benefit of using Elastic APM. We already resolved a misconfiguration issue for our service and database in regards to database connection handling and connection limits, as well as fixing a potential bug with data loss due to behaviour of the HTTP server implementation and context cancellation.
Overall, this chapter is more of a cautionary tale what happens if you aren’t super familiar with some internals of database connection handling and http.Request context. Elastic APM was just the tool that pointed us to our pitfalls.
This article is part of a Advent of Go Microservices book. I’ll be publishing one article each day leading up to christmas. Please consider buying the ebook to support my writing, and reach out to me with feedback which can make the articles more useful for you.
All the articles from the series are listed on the advent2019 tag.
While I have you here...
It would be great if you buy one of my books:
- Go with Databases
- Advent of Go Microservices
- API Foundations in Go
- 12 Factor Apps with Docker and Go
For business inqueries, send me an email. I'm available for consultany/freelance work. See my page for more detail..
Want to stay up to date with new posts?
Stay up to date with new posts about Docker, Go, JavaScript and my thoughts on Technology. I post about twice per month, and notify you when I post. You can also follow me on my Twitter if you prefer.