
Real world optimisation
Don’t optimize prematurely - but have a plan how you’re going to do it. With the services I write, a lot of the code may be clear, simple and readable over actually optimizing for speed. Sometimes, the difference between that code, and the optimized code, is a short refactor.
One of the services I write, is a comments service for the Slovenian national TV & Radio station, RTV Slovenia. On a typical day, the Elastic APM transactions end up being something like this:
![]()
What this tells us, that we optimized the hot path down to a 1ms average, with a 99 percentile time of 4ms. A 99th percentile means that 99% of requests took less than 4ms, while 1% of requests took longer.
We can also see that the list call has the biggest impact. When
considering all requests, the impact is the commulative time used for all
requests against an endpoint. It’s calculated by multiplying the average
duration with transactions per minute.
To optimize something, you must first understand how something works. The
comments API has two listing endpoints, list and thread. The list
endpoints returns all comments and their replies in a selected order,
while the thread endpoint returns only the replies to a single comment,
or a list of top-level comments without the replies.
For each reply, the list endpoint retrieves the parent comment for
display. This step of the API call had a pretty un-optimal O(N) situation
where the service retrieved the parent comment for each reply in the
list, individually.
for key, comment := range result.Comments {
if comment.SelfID > 0 {
reply, err := svc.comments.Get(ctx, comment.SelfID, currentUser)
if err == nil && reply != nil {
reply.Comments = &types.CommentListThreadShort{
CommentListShort: &types.CommentListShort{
Count: threadCounts[comment.SelfID],
},
}
result.Comments[key].Parent = reply
}
}
}
There are a few code smells around this code:
- The
errnever got logged or returned, - The naming for
replyis misleading, as this is a parent comment - Cosmetic issues like nesting depth
So, my bet is, that by collecting all the valid SelfIDs beforehand, I can optimize this down from an O(N) into an O(1) operation, optimizing the service as we go, and improving the code quality as I do.
I need to:
- Collect the SelfID values together into a slice,
- Issue a “multi-get” query against the database,
- Read the parents from a simple map[ID]Comment
Here is where the “planning” part comes in - I already had a multi-get call for comments implemented due to how the service itself structures comment metadata, and then retrieves the comment body in the second step. The normalized comment data meant I had to implement a multi-get for use in all the main comment list responses, and now I can re-use it here to retrieve all the parent comments.
parents := make(map[int64]*types.Comment)
parentComments := []*types.Comment{}
parentIDs := []int64{}
for _, comment := range result.Comments {
if comment.SelfID > 0 {
parentIDs = append(parentIDs, comment.SelfID)
}
}
if err := svc.comments.Comments(ctx, &parentComments, parentIDs, currentUser); err != nil {
return err
}
for _, parent := range parentComments {
parents[parent.ID] = parent
}
Before the loop we first collect all valid SelfID values into
parentIDs, retrieve all the comments having those ID values into the
parentComments slice, and finally, filling out a map, parents, with
the results. This is also generally safer than the previous code, as
possible errors are returned.
We could improve the allocations further to avoid the append call, but
given the very limited response sizes, pre-allocating the parentIDs slice
just extends the code without much benefit. It may be a valid
optimisation technique for other cases.
Finally, by restructuring the initial code a bit to read from the
parents map, we fill out the values we need without any additional
database lookups. All the data has been pre-filled with a single DB
query.
for key, comment := range result.Comments {
if comment.SelfID == 0 {
continue
}
if parent, ok := parents[comment.SelfID]; ok {
parent.Comments = &types.CommentListThreadShort{
CommentListShort: &types.CommentListShort{
Count: threadCounts[comment.SelfID],
},
}
result.Comments[key].Parent = parent
}
}
Finally, after the deploy, we can take a look at the logged transaction durations. There has been a strong improvement over the board, as we optimized the endpoint with the highest impact. Overall the optimisation reduced the 95th and 99th percentile noticably, all with little effort.
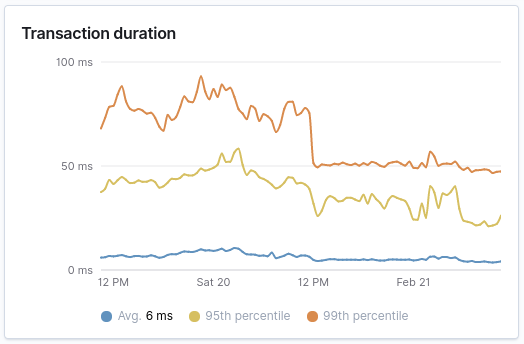
All in, I probablly haven’t needed to optimize this, since the service itself doesn’t accrue any significant penalty in operations. With a few percent of CPU in use over the service group, the change itself doesn’t have a real impact on cost, but as it goes, it immediately improves the user experience (lower latency) and reduces technical debt.
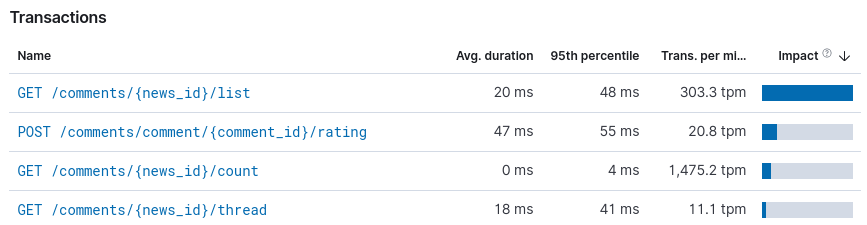
After running the service for some time, we can see that the API call latency dropped to an average of 20ms (down from 33ms) and the 99th percentile decreased to 48ms (down from 79ms). We have optimized the service, to respond -39% as fast - OVERALL - and that’s amazing. At a big scale, these could be significant gains. And they all come from a single endpoint.
It’s clear that code with which we started is only waiting for a refactor down the line. If you can clean up the code regularly and optimize small inefficiencies like this, hopefully outgrowing your infrastructure becomes harder to do. After all - we don’t code for self-punishment, so it’s best to avoid these situations with regular maintenance work.
While I have you here...
It would be great if you buy one of my books:
- Go with Databases
- Advent of Go Microservices
- API Foundations in Go
- 12 Factor Apps with Docker and Go
For business inqueries, send me an email. I'm available for consultany/freelance work. See my page for more detail..
Want to stay up to date with new posts?
Stay up to date with new posts about Docker, Go, JavaScript and my thoughts on Technology. I post about twice per month, and notify you when I post. You can also follow me on my Twitter if you prefer.